MIT 6.S081 Lecture 3 Notes
6.S081第三课,主要教授操作系统组织与系统调用。
阅读xv6课本第二章,观看课程视频。Unix系操作系统的主流设计是宏内核 monolithic kerel。xv6的设计也是如此。
Abstracting physical resources
一些嵌入式设备或实时系统允许应用程序直接与硬件资源交互,以实现较高或可预测的性能。但在多程序时,这样的实现未必能很好处理时间分享(每个程序都想要更高的隔离性)。所以为了达到强隔离性,需要禁止程序直接读写硬件资源,并将资源抽象化。
比如提供系统调用与文件系统抽象程序与存储器的交互。同样,Unix透明地在进程间切换物理CPU,保存与恢复寄存器状态。还有一个例子,进程通过 exec 加载内存映像,而不是直接与物理内存交互(当然还有与存储器的交互,文件系统上的可执行程序),这是虚拟内存的抽象。Unix的文件描述符不仅抽象了许多细节,也定义了一个简化的交互方式。总之,将繁重复杂的工作交给内核。当然Unix的接口不是唯一的抽象方式,但不失为良好的设计,满足了程序员的便利与强隔离性的可能。
User mode, supervisor mode, and system calls
强隔离性保证OS不受程序bug影响,且可以清理错误程序与执行其他程序。所以应用不能修改(甚至不能读)OS的数据结构与指令,也不能读写其他进程的内存。CPU提供了隔离性的硬件支持。例如,RISC-V CPU可以在三种模式下执行指令:machine mode,supervisor mode 和 user mode。
| mode | decription |
|---|---|
| machine mode | Instructions have full privileg; a CPU starts in machine mode; mostly intended for configuring a computer; xv6 executes a few lines in machine mode and then changes to supervisor mode |
| supervisor mode | CPU is allowed to execute privileged instructions |
| user mode | If an application in user mode attempts to execute a privileged instruction, then the CPU doesn’t execute the instruction, but switches to supervisor mode so that supervisor-mode code can terminate the application |
应用只能执行 user mode 指令,例如加数字,也就是在用户空间运行。当然软件在 supervisor mode 下可以执行 privileged instructions,也就是所谓的在内核空间运行,陷入内核态。
应用为了调用内核函数必须转交给内核,间接调用。CPU提供 ecall 指令,用以将CPU从 user mode 切换为 supervisor mode 并进入内核指定的 entry point。一旦CPU切换为 supervisor mode,内核可以验证系统调用的参数(例如确认传入地址是否为应用内存),决定是否允许请求的操作,拒绝或执行之。永远是内核控制切换 supervisor mode 后的 entry point,即系统调用的代码位置;如果应用能决定,那么恶意程序就可以进入一个跳过参数验证的内核位置。
想象一下,假如没有硬件支持的 kernel/user 模式与虚拟内存,可以实现隔离吗?可以。用 strongly-typed programming language 写OS,例如 singularity OS,电脑就成了一个任务控制块TCB。但用硬件支持是通用方案。
Kernel organization
一个核心设计问题是OS什么部分代码应该在 supervisor mode 下运行。最简单的想法,整个OS都处于内核,那么所有系统调用的实现肯定也在 supervisor mode 下。这种组织是宏内核 monolithic kernel。这种设计便于OS的各部分代码协作。例如,一个OS可能有文件系统与虚拟内存系统共享的buffer缓存。缺点是OS不同部分的交互。OS开发者很容易犯错,而且是 fatale error。因为错误发生在 supervisor mode 下会导致内核崩溃,计算机停止工作,所有应用崩溃,不得不重启。
为了降低内核出错的风险,设计者也可以最小化在 supervisor mode 下运行的 OS 代码,将大量OS代码运行于 user mode。这种设计是微内核 microkernel。例如,文件系统作为用户级进程运行,OS服务都作为一个个服务进程运行。为了允许应用与文件服务进程交互,内核提供一个IPC机制,在 user mode 的进程间传递消息。微内核的接口由一些 low level 函数组成,如开始一个应用、发送消息、获取设备硬件等。这种设计可以让内核十分简单,大部分OS代码都是用户级别服务。
现实世界中,宏内核与微内核都十分流行。许多Unix系内核都是宏内核,如 Linux (虽然一些OS函数作为用户级服务运行,如 windowing system)。Linux为操作系统密集型应用程序提供了高性能,部分原因是内核的子系统可以紧密集成。像Minix,L4 和 QNX 都是微内核,且广泛部署在嵌入式设备上。有OS是微内核,但为了性能原因在 kernel space 运行用户级服务。有OS是宏内核,因为历史原因无法迁移到微内核架构,许多特性太过重要无法重写代码改变设计。这本书专注两种设计的相同思想,即OS的核心思想。xv6实现为宏内核,如大部分Unix OS,但不提供许多服务,因此比许多微内核OS小,概念上仍是宏内核。
Process overview
内核实现进程机制往往用到 user/supervisor mode flag ,地址空间与线程的时间切片。硬件实现了页表,OS利用其实现进程的地址空间。RISC-V的页表将虚拟地址转为物理地址。xv6为每个进程维护一个页表。顺带一提,xv6定义的地址空间布局与CSAPP中的不一样(可以看CSAPP的进程地址空间布局图)。从地址0开始,首先是指令区,然后是全局变量区,然后是栈,最后是堆区。
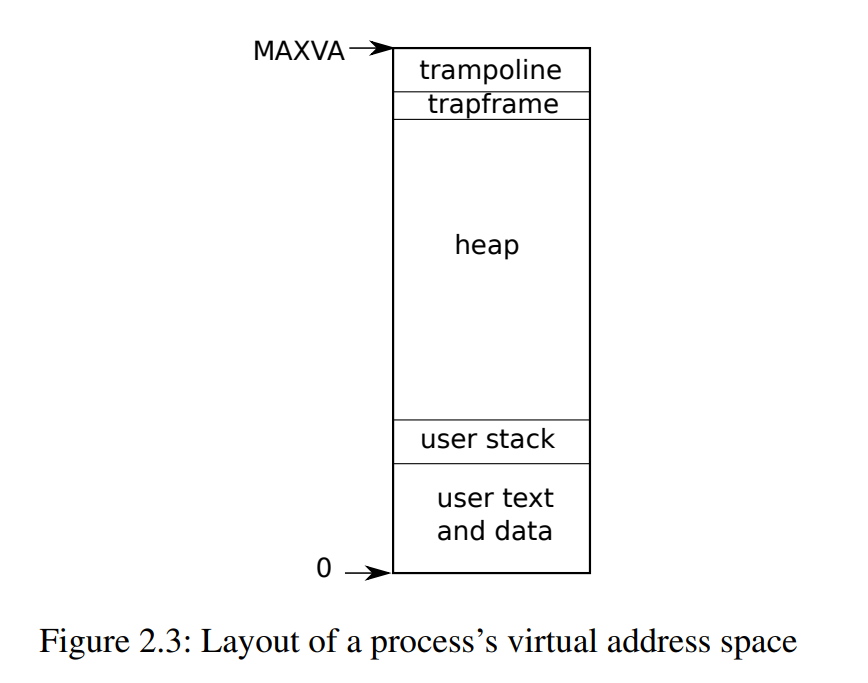
有许多因素限制进程的地址空间:64位的机器字长;硬件用虚拟地址的低39位在页表中查找;xv6只用其中的38位。因此,最大地址为 2 ^ 38 - 1 == 0x3fffffffff。在地址空间的顶端,xv6为 trampoline 与 trampframe 各保留一个页的内存。xv6用这两个页在用户态与内核态间转换;其中 trampoline 页包含两态间转换的代码;trampframe包含用户进程需要保存与还原的状态(PC 寄存器 EFLAGS)。
xv6内核为每个进程维护状态信息于 struct proc 中,定义在 kernel/proc.h 文件。一个进程最重要的内核状态就是页表、内核栈还有运行状态。每个进程都有一个线程执行当前指令。局部变量与函数调用返回地址就保存在线程栈中。每个进程有两个栈,用户栈与内核栈(p->kstack)。当进程执行用户指令,使用 user stack 且 kernel stack 为空。当进程进入内核(系统调用或终端),内核代码执行于进程的 kernel stack;当进程陷入内核态,其 user stack 仍然保留数据,但不被使用。由于 user stack 不可见 kernel stack,所以即使进程破坏 user stack 而内核也不受影响。
进程通过 RISC-V 的 ecall 指令进行系统调用。这个指令提升硬件优先级,改变PC为内核定义的 entry point。而 entry point 的代码切换到了 kernel stack 并执行系统调用的内核实现。系统调用完成,内核通过 sret 指令切回 user stack 返回用户空间。这个指令降低硬件优先级,恢复执行系统调用后的用户代码。内核态的进程常因IO而阻塞,因IO完成而回用户态。
结构体 proc 的 state 字段指示进程状态是 allocated, ready to run, running, waiting for I/O, or exiting;字段 pagetable 以 RISC-V 硬件期望的形式持有页表,进程处于用户态时xv6让相关硬件使用这个字段。进程页表也是已分配物理页地址的记录表。
总之,进程两个核心概念:地址空间给其独占的幻觉,线程给其独占CPU的错觉。在xv6中一个进程只有一个地址空间与一个线程,但其他操作系统一个进程可以有多个线程以利用多CPU。
Code: starting xv6, the first process and system call
课程描述xv6内核是如何启动并运行第一个进程的。
当一个RISC-V电脑通电,完成初始化后运行一个存于ROM的boot loader。boot loader 将 xv6 内核加载入内存。在 machine mode 下,CPU从 _entry(位于 kernel/entry.S:7)执行 xv6 代码。最开始寻页硬件是关闭的,虚拟内存直接映射到物理内存。
boot loader 将xv6内核加载入从 0x80000000 开始的物理内存。低于这个地址的内存用于包含 IO 设备。
位于 _entry 的指令建立一个栈,以便 xv6 可以运行 C 代码。xv6为初始栈 stack0 声明空间,位于 kernel/start.c 11行中。然后,将地址 stack0+4096 加载到栈顶指针寄存器 sp 中,因为 RISC-V的栈增长是向低地址的(和CSAPP中一样)。现在内核有了栈,_entry 调用位于 kernel/start.c 的start函数。
函数 start 完成一些仅允许于 machine mode 下的配置,然后切换为 supervisor mode。RISC-V 提供 mret 指令以进入 supervisor mode。这个指令常使用场景是: supervisor mode 下通过调用进入 machine mode 然后用 mret 返回。虽然 start 函数没有之前为 supervisor mode 的调用者(自开机起都是 machine mode),但仍会假装有,并设置:将寄存器 mstatus 里的先前优先级设为 supervisor,将 main 函数地址写入寄存器 mepc 以设置返回地址到 main 函数中,向页表寄存器 satp 写 0 以关闭supervisor mode 的虚拟地址翻译,代理(delegate)所有supervisor mode 下的中断与异常。
在进入 supervisor mode 前,函数 start 还会编程时钟芯片(the clock chip)以生成计时器终端(timer interrupts)。在完成以上工作,函数start 通过调用 mret “返回” 到supervi mode。这将使PC改变为 main 函数地址,以上说的 main 函数位于 kernel/main 中。
当 main 初始化几个设备与子系统后,通过调用 userinit (kernel/proc.c:226) 以创建第一个用户进程。这第一个进程执行一个用 RISC-V 汇编写的小程序 initcode,会执行xv6中的第一个系统调用。代码在汇编 user/initcode.S ,具体是,准备系统调用参数,加载 exec 的系统调用号 SYS_EXEC 入寄存器 a7 中,然后调用 ecall 指令执行 exec 重入内核,通过 exec 加载 /init 程序。
# Initial process that execs /init.
# This code runs in user space.
#include "syscall.h"
# exec(init, argv)
.globl start
start:
la a0, init
la a1, argv
li a7, SYS_exec
ecall
# for(;;) exit();
exit:
li a7, SYS_exit
ecall
jal exit
# char init[] = "/init\0";
init:
.string "/init\0"
# char *argv[] = { init, 0 };
.p2align 2
argv:
.long init
.long 0
内核使用寄存器a7中的系统调用号,调用指定系统调用。文件 kernel/syscall.c 中的系统调用表将 SYS_EXEC 映射到函数 sys_exec ,也就是内核将调用的函数实现。一旦内核完成 exec ,就返回用户态进入到 /init 进程中。这个 /init 进程将创建一个新的控制台设备文件(if needed),将其打开作为文件描述符0,1,2(标准输入输出错误流),然后在控制台上开始一个 shell 程序。至此,系统启动完成。p.s. 在Linux讨论下常说的 /init 进程为进程树的根,这个启动过程正好描述了原因。
Security Model
也许好奇OS如何解决易错和恶意代码。这个话题统称为安全话题。我们需要用一个高层级的视角去看OS设计中的安全假设与目标。
OS必须假设一个进程的用户级代码会最大限度地尝试毁坏内核与其他进程。例如,用户代码对指向合法地址空间外的地址的指针解引用;用户代码尝试执行任何RISC-V指令,甚至是非用户级指令;用户代码尝试读写RISC-V的控制寄存器;尝试直接获取设备硬件;尝试向系统调用传一些特殊的参数,以使内核崩溃或完成未定义的行为。内核的目标就是限制用户进程,让其能做的只有读、写或执行其用户内存上的数据与代码,使用32个RISC-V的通用寄存器,仅通过系统调用允许的行为来影响内核与其他进程。内核必须限制进程的其他行为,这是内核设计的绝对准则。
内核代码则假定被良好编写,没有bug,绝对不含恶意代码。硬件层面上,RISC-V的CPU,RAM,硬盘等均被假设如文档声称的良好运作,没有硬件bug。
当然现实中,OS很难预防用户通过消耗内核保护的资源(硬盘空间 CPU时间 进程表空槽等)以无用化系统或使系统崩溃。设计完全无bug的硬件与写无bug的内核代码也是不可能的;恶意代码作者如果熟悉内核和硬件的bug,还是能利用之。所以现实中常在内核中加入 safegurad 对抗可能的bug,如 assertions, type checking, stack guard pages 等。p.s. 防止栈溢出,CSAPP里不也提到金丝雀防卫标志。最后,用户与内核代码的区别有时是模糊的:有些 privileged 用户级进程可能提供关键服务,有效成为OS的一部分;有些 OS privileged 用户代码可以向内核中插入新代码(如Linux’s loadable kernel modules)。
Real world
xv6使用的进程概念与大部分OS相似。但现代OS支持一个进程内多线程,以允许一个进程利用多个CPU。支持多线程要求一些xv6没有的机制,包括潜在接口的改变(例如,Linux’s clone 作为 fork 的变种),以控制进程内线程共享的部分。
Conclusion
这节课主要讲OS的设计,OS抽象的工作,硬件上的不同模式的支持,宏/微内核,进程的内存布局与状态,通过xv6代码示例讲OS如何启动,OS的安全假设与目标等。