MIT 6.S081 Lecture 4 Notes
6.S081第四课,教授地址空间、RISC-V的分页硬件与 xv6 虚拟内存代码。阅读xv6课本第三章,观看课程视频。xv6的细节很多,这里只挑重点讲述。
Goal: Isolation
为了实现进程关于内存的隔离,一般OS都是利用分页硬件实现。
内核指示MMU如何将虚拟地址映射为物理地址。MMU维护页表进行映射,而每个地址空间都有一个独立的页表。
CPU -> MMU -> RAM
Virtual Address -> Physical Address
只有内核才能编程MMU,OS以此实现许多特性。部分虚拟地址被限制为内存独有,内核通过MMU可以限制用户代码使用的虚拟地址。
Virtual memory in RISC-V
RISV-V 以 4KB 作为页的大小单位 4 KB = 12 bits per byte ,因此64位的机器字长除去低 12 位,剩余的 52 位用于寻找对应的物理页。
Page Table Entry
实际上 RISC-V 支持多种虚拟地址模式,如Sv32 , Sv39, Sv48。这里的数字指示虚拟地址的位数。课程教授以Sv39为例子,39 - 12 = 27 ,即真实用于寻页的位数为 27。
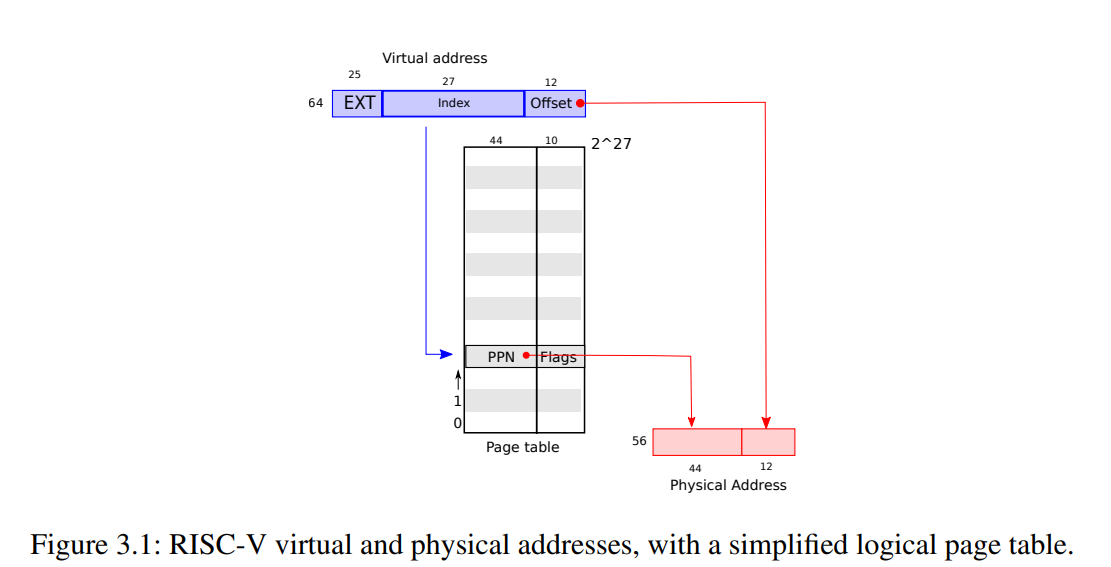
如Figure 3.1 所示,页表的简单逻辑就是用虚拟地址的index位查表得到 PTE (Page Table Entry),然后用 PPN (Physical Page Number) + Offset 组成物理地址。其实这里的每个 PTE 长度仍为 64 位,但是高位没有用,低位用作Flag指示页的元信息,是否可读可写等。
当然,如果页表是一个数组,会浪费很多空间。
2^27 is roughly 134 million
64 bits per entry
134 * 8 MB for a full page table
每个应用需要一个地址空间,每个地址空间需要一个页表,就需要用到 1 GB 的空间。许多小应用根本用不到,造成空间浪费。实际上,RISC-V的Sv39虚拟地址会用到三级页表(Sv48用到四级)。
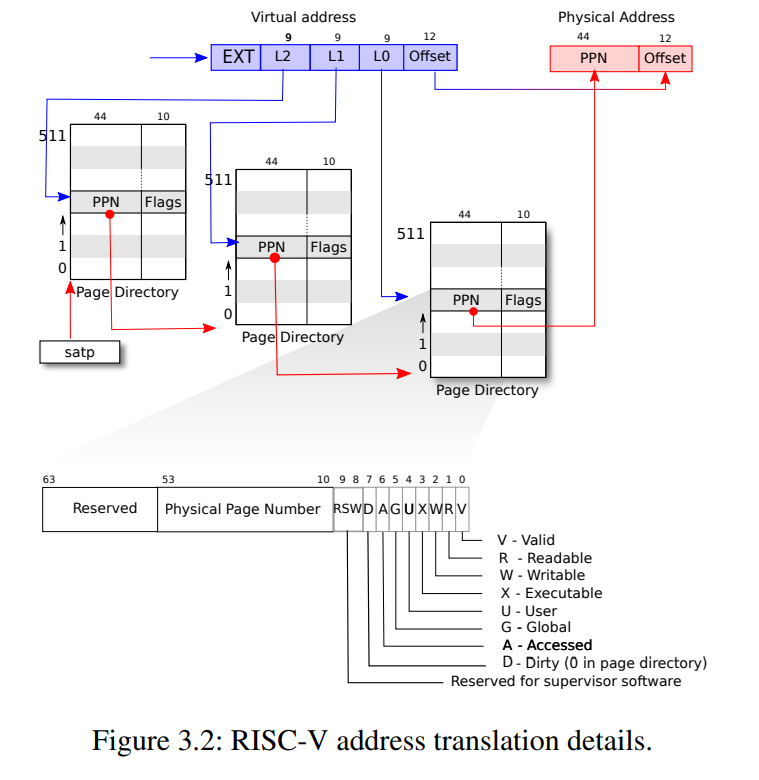
每个PD(Page directory)拥有512个PTEs,一个PTE指向另一个PD或者叶节点。最多的叶节点PTEs数目为 512 * 512 * 512 == 2 ^ 27,页表大小没有变化,但是一些PTE不需要存在,使得页表可以动态化地适应小程序。另外,每个PD或页节点的大小为 512 * 64 bit = 4096 byte恰好为一页大小,满足RAM按页为粒度划分的规则。
How do we program the MMU?
页表本质上仍在RAM中,寄存器 satp 指向根PD的物理地址,MMU通过读寄存器内容找到页表,通过写 satp 切换不同地址空间的页表。以下为RISC-V satp的内容。可以看到低44位是PPN,用于索引。

硬件通过页表树找到PTE,将最近使用的PTE存入TLB(Translation Look-aside Buffer)中,以便查询缓存,切换页表时,TLB原有的缓存内容也会失效。RISC-V提供指令 sfence.vma 清空当前CPU的MMU的TLB内容。为了避免清空整个TLB,RISC-V CPU可以支持 ASID (addres space identifier),内核可以仅清空特定地址空间的TLB entry。
PTE Flags
这里用表格简单讲一下PTE的几个常用的Flags位。
| Flag | Effect |
|---|---|
| V | indicates whether the PTE is present: if it is not set, a reference to the page causes an exception (i.e. is not allowed). |
| R | controls whether instructions are allowed to read to the page. |
| W | controls whether instructions are allowed to write to the page. |
| X | controls whether the CPU may interpret the content of the page as instructions and execute them. |
| U | controls whether instructions in user mode are allowed to access the page; if PTE_U is not set, the PTE can be used only in supervisor mode. |
| G | prevents TLB flushes of a PTE |
老生常谈的是,如果 PTE_V 未设置,会产生页错误,进程陷入内核,要么内核报错并kill进程,要么从磁盘加载一页作为PTE然后重启进程。
Why use virtual memory while in kernel?
在用户态用虚拟内存显然有利于隔离。如果内核态使用物理内存呢?
当然是可以如此设计。但大部分标准内核仍然用虚拟地址。
- 每次系统调用都需要关闭和打开VM,在硬件上代价太大。
- 难以处理跨页表的系统调用参数。(lame,未必难)
- 内核代码本身从虚拟地址获益,标记数据与代码页,unmap kernel stack 的页(便于debug),同时在用户与内核态 map 一页(使用 trampoline 便于两态转换)。
- 让内核支持不同的硬件物理地址布局太过麻烦。
- 内核也需要分配内存。
使用虚拟内存使许多特性成为可能,如
- 物理内存不用连续,防止碎片
- lazy allocation
- copy-on-write fork
Virtual memory in xv6
以 xv6 为例,教授内核地址空间与用户地址空间的布局。书中还有详细的代码导读。
kernel page table
xv6内核的地址空间布局如图 Figure 3.3 所示。
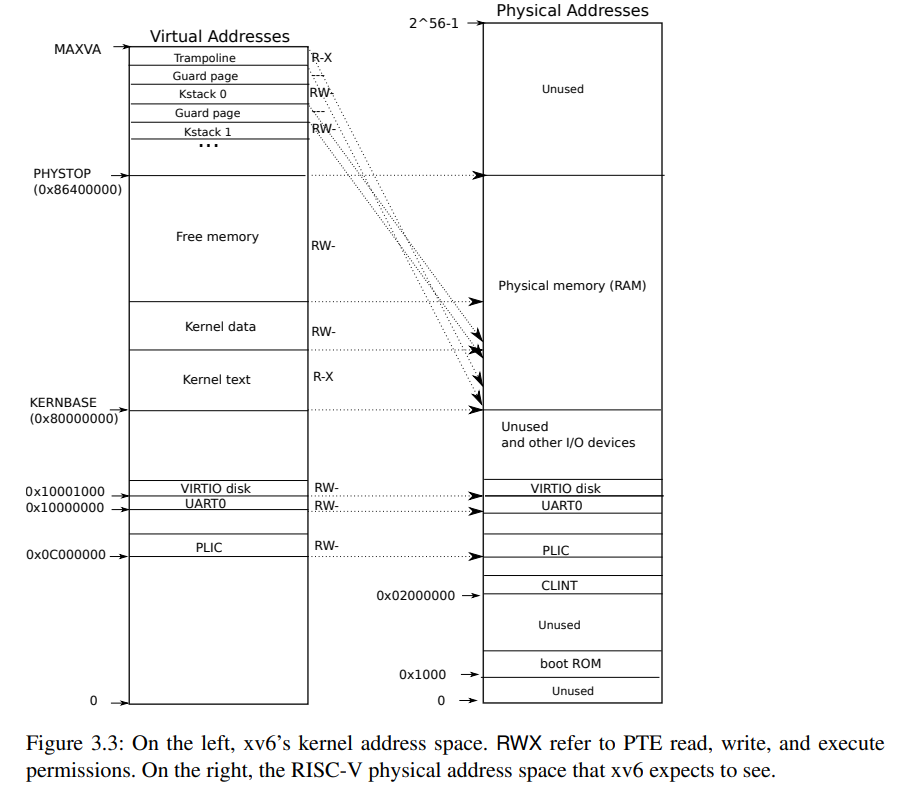
图右 RAM 是 QEMU 模拟的计算机 RAM,范围从 0x80000000 直到 0x86400000。QEMU 模拟了如硬盘接口的I/O设备,映射到 0x80000000 以下的内存空间。内核通过读写这部分特殊的虚拟地址,与设备硬件交互(而不是与RAM)。这部分在书第四章有详细解释。
内核获取 RAM 与内存映射的设备寄存器都是 “direct mapping”,即资源虚拟地址等价其物理地址。例如,内核本身位于 KERNBASE=0x80000000 的物理地址与虚拟地址上。如此可以简化内核代码对于物理内存的读写。例如,系统调用 fork 为子进程分配用户内存,可以得到对应内存物理地址;fork 复制父进程用户内存给子进程时,可如虚拟地址一样直接使用地址。内核虚拟地址也有不是直接映射的,
-
The trampoline page. 位于虚拟地址空间顶端;用户页表有相同的映射。第四章有详细解释。这里仅关心映射。trampoline对应物理页被映射了两次,一次是内核虚拟地址空间顶端,一次是用户空间的映射。
-
The kernel stack pages. 每一个进程拥有自己的 kernel stack。位置较高以便 xv6 在下方留下一个未映射的 guard page。而 guard page 的 PTE 是 invalid (i.e., PTE_V is not set),以便一旦内核栈溢出,可以引发异常使内核 panic。没有这一层保护,栈溢出可能重写其他内核内存。所以 panic crash 是可取的。
之所以 xv6 不使用直接映射 stack page 的设计,也是方便 guard page 为未映射的页。另外注意 xv6 为 trampoline 页和kernel text 页分配的权限都是R-X,而除了 guard page 其他都是 RW- 权限。
process addres space
每个进程有独立的页表,进程切换时,硬件也会切换页表。用户地址空间布局如图Figure 3.4 所示,
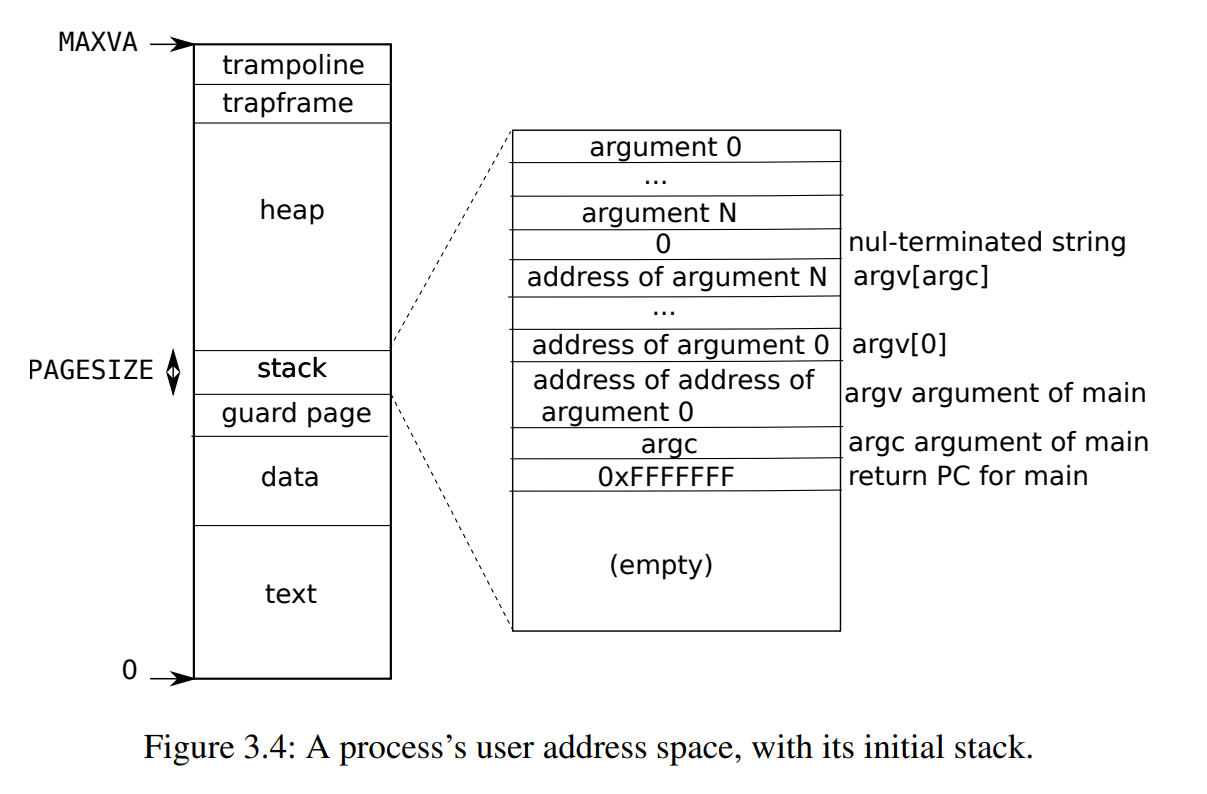
地址空间从 0 开始,直到 MAXVA 为止。文件 kernel/riscv.h 中声明了宏 MAXVA ,原则上允许进程地址最大为 256 Gigabytes。所有进程地址空间顶端的trampoline页都会内核地址空间中再次映射。图中也示例了栈大小为一个页,还有 main(argc, argv) 参数在栈中的布局。xv6用清空 PTE_U 位的页作为 guard page,检测栈溢出。现实世界的OS可能会为栈分配更多内存。
Real world
多数OS都通过分页完成进程地址空间隔离。
xv6 内核通过虚拟地址到物理地址直接映射进行简化,并且假设物理 RAM 位于地址 0x8000000。这也是内核代码期望加载处。这在QEMU下可以工作,但现实硬件会将 RAM 与 设备放置在不可预测的地址(CSAPP也有提到,防止栈攻击)。更专业的内核会利用页表,将任意的硬件物理内存布局转为可预测的内核虚拟地址布局。
RISC-V 提供了物理地址级别的保护,但 xv6 没有用到这个特性。
有些具备较多内存的机器可能会使用 RISC-V 提供的 super pages,即更大的页。
xv6 内核缺乏 malloc-like 内存分配,无法对较小的对象分配较少的内存,使得内核无法使用一些要求动态内存分配的复杂数据结构。内存分配的基础问题就是有效使用有限的内存,对未来未知请求充分回应。今天普遍关心速度效率胜过空间效率。一个更复杂的内核倾向于分配不同大小的块,而不是像 xv6 内核仅分配 4096 bytes 的页。真实内存的分配器需要同时处理大块与小块。
Conclusion
这节课主要从RISV-V与xv6两个角度,通过硬件与软件讲授虚拟内存的知识。也介绍了 xv6 距离现实OS内核的差距。多级页表的知识本科大多学过,其设计的思想是动态使用PTE。硬件MMU的工作主要是通过 satp 切换页表,查找页完成 VA -> PA 转换。而 TLB 支持部分清空的特性应该可以被软件利用,写出内存友好的代码。内核代码使用虚拟地址也是设计上的取舍,xv6的直接映射与 trampoline 重复映射虽然对比real world OS 比较简单,但也体现了内核对于虚拟内存机制的利用。